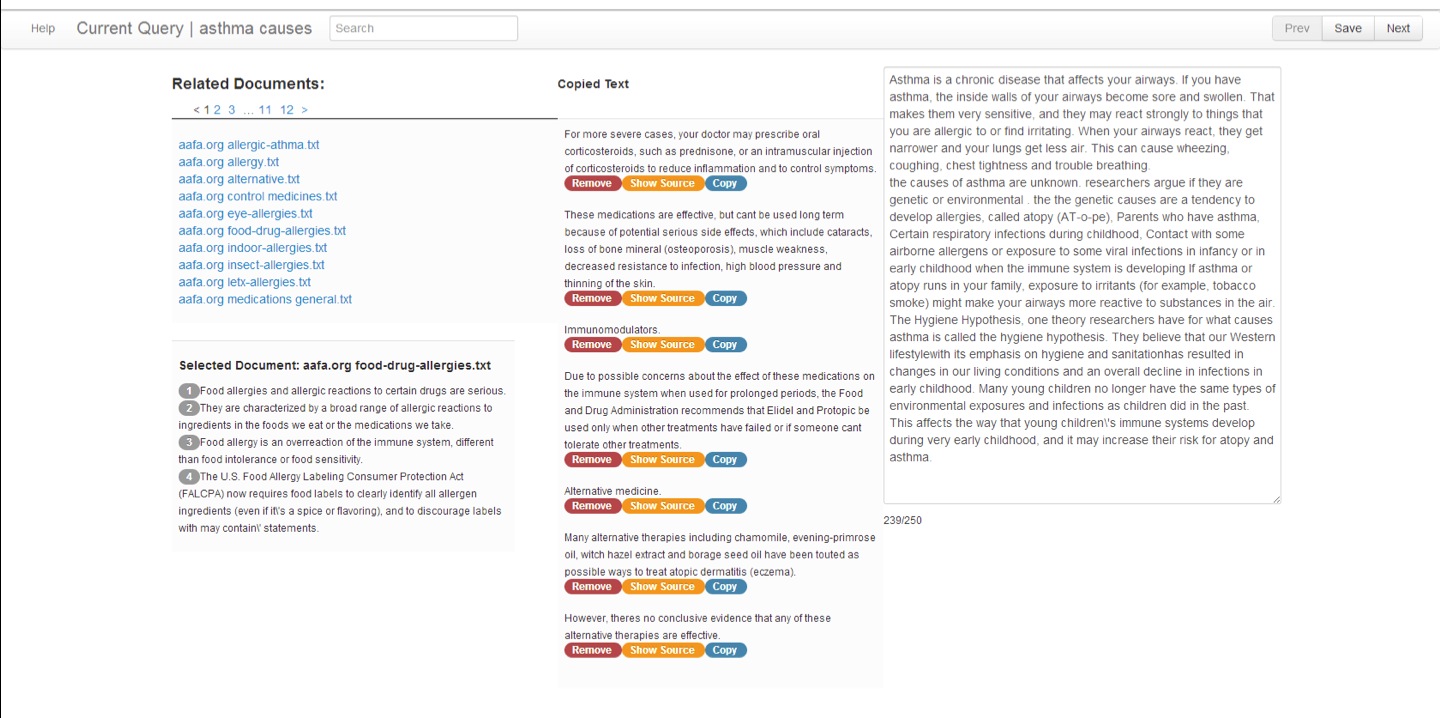
The following shows manual summaries created in answer to the following query chain:
"
obesity screening -> body mass index -> BMI Validity".
We annotated the summaries to highlight how the exploration process develops:
- We show with underlining terms which correspond directly to the current query
- We show with italics terms which have likely triggered the curiosity of the reader and led to asking the next query.
.
Q1: obesity screening
Body mass index (BMI) is a
measure used to determine childhood overweight and
obesity.
A child's
weight status is determined using an age- and sex-specific percentile for
BMI rather than the
BMI categories used for adults because children's body composition varies as they age and varies between boys and girls. For children and adolescents (aged 2-19 years):
Overweight is defined as a
BMI at or above the 85th percentile and lower than the 95th percentile for children of the same age and sex.
Obesity is defined as a
BMI at or above the 95th percentile for children of the same age and sex.
BMI is not a perfect
measure, but rather a helpful
indicator. It doesn't consider things like being muscular or having a larger than average body frame and because growth patterns vary greatly among children. As a result, doctors also factor a child's growth and development into consideration when
screening for
overweight and
obesity.
Obesity screening of adults using
BMI may be less accurate for adults, due to the coarseness of the
measurement: Heavily muscled athletes may have a high
BMI, as may women who enter menopause, who tend to gain
weight due to increased water retention.
Q2: body mass index
The
body mass index (BMI), or Quetelet
index, is a measure for human body shape based on an individual's
mass and height. Devised in the mid 1800s by Adolphe Quetelet during the course of developing "social physics", it is defined as an individual's
body mass divided by the square of their height, the units being kg/m^2.
BMI was explicitly cited as being appropriate for population studies, and inappropriate for individual diagnosis.
BMI provides a simple measure of a person's thickness, allowing health professionals to discuss
overweight and
underweight problems more objectively with their patients. However,
BMI has become controversial because many people, including physicians, have come to rely on its apparent
authority for medical diagnosis. However, it was originally meant to be used as a simple means of classifying sedentary individuals, or rather, populations, with an average
body composition. For these individuals, the current value settings are as follows: a
BMI of 18.5 to 25 may indicate optimal
weight, a
BMI lower than 18.5 suggests
underweight, a number above 25 may indicate
overweight and a number above 30 suggests
obesity.
For a given height,
BMI is proportional to
mass. However, for a given
mass,
BMI is inversely proportional to the square of the height. So if all
body dimensions double, and
mass scales naturally with the cube of the height, then
BMI doubles instead of remaining the same. This results in taller people having a reported
BMI that is uncharacteristically high compared to their actual body fat levels.
Nick Korevaar (a mathematics lecturer from the University of Utah) suggests that instead of squaring the
body height or cubing the
body height, it would be more
appropriate to use an exponent of between 2.3 and 2.7 (as originally noted by Quetelet).
Q3: BMI Validity
BMI has become
controversial because many people, including physicians, have come to rely on its apparent numerical authority for medical diagnosis, but that was never the
BMI's purpose; it is meant to be used as a simple means of classifying sedentary populations with an average body composition. In an article published in the July edition of 1972 of the Journal of Chronic Diseases, Ancel Keys explicitly cited
BMI as being
appropriate for population studies, but
inappropriate for individual diagnosis. These ranges of
BMI values are
valid only as statistical categories
While
BMI is a simple, inexpensive method of screening for weight categories, it is not a
good diagnostic tool: It does not take into account age, gender, or muscle mass. Nor does it distinguish between lean
body mass and fat mass. As a result, some people, such as heavily muscled athletes, may have a high BMI even though they don't have a high percentage of body fat. In others, such as elderly people,
BMI may appear normal even though muscle has been lost with aging. Take for example, basketball player Michael Jordan: ''When he was in his prime, his
BMI was 27-29, classifying him as overweight, yet his waist size was less than 30,'' says Michael Roizen, MD.
Another
shortcoming of
BMI is that your health is not only affected by excess
body fat, but also by where the fat is located. People with apple shapes are at higher risk for health problems associated with being overweight.
As a result of these problems, health professionals need to do further
assessments to fully evaluate health risks. These
assessments would include measurements of
body fat percentage, diet history, exercise patterns, and family history.
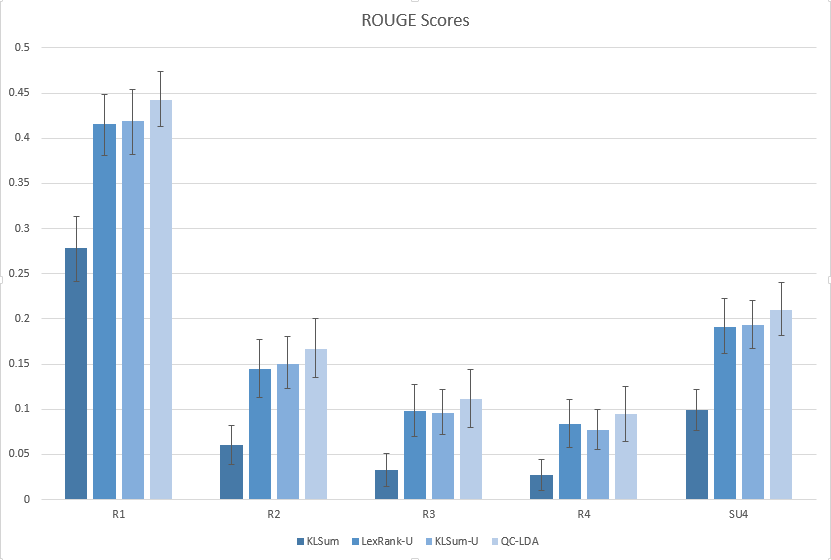 The results show the ROUGE-recall metrics with stop words removed and all content words stemmed.
The results show the ROUGE-recall metrics with stop words removed and all content words stemmed.