Scaling-Up Neural Networks¶
Now that we are familiar with sequence to sequence models let’s discuss how to scale them to real world problems. In the previous example we used a very small vocabulary (4 symbols $“a,b,c,d”$) but when dealing with tasks such as machine translation our vocabulary can contain thousands of unique words, that means that the last layer of our network must be the dimension as the size of the vocabulary and $softmax$ must be applied on an extremely long vector. When training a network we cannot afford such a costly operation.
That's why hierarchical softmax was invented, it can increase softmax computation time by up to $log(n)$ without compromising too much of the network reliability.
The Softmax Function¶
The softmax function, or normalized exponential is used to transform a $n$ dimensional vector into a probability over $n$ classes, formally it is defined as: $P(class=i | x) = \dfrac{e^{x_i}}{\sum_{j=1}^ne^{x_j}}$.
NumPy code for SoftMax:
import sys
sys.argv.append('--dynet_mem')
sys.argv.append('5000')
import numpy as np
def softmax(x):
return np.exp(x) / np.sum(np.exp(x), axis=0)
In order to calculate the softmax we need to $O(n)$ time. Let's see how can we reduce it to $O(log(n))$.
The Hierarchical Softmax Function¶
Let's see what happens to the computation complexity if we divide our vocabulary into to 2 equal non-overlapping groups, and change the classification process to first selecting the group $P(group=i|x)=softmax(x*W_{groupselect}+b_{groupselect})$ and then selecting the word from the group $P(word=w|x) = P(group=i|x)P(word=w|x, group=i)$. Before the computation required us to was $|x||n|+|n|$ operations. After the splitting selecting the group takes $2|x|+2$ operations and selecting the correct item from the group takes $\dfrac{n}{2}|x|+\dfrac{n}{2}$ operations. We reduced the total operations to $(2+\dfrac{n}{2})|x|+2+\dfrac{n}{2}$, for large vocabularies this could mean great reduction in computation time. We can segment our vocabulary however we like and achieve up to $log(n)$ speedup.
This is the hierarchical softmax function first it arranges the output vocabulary in an hierarchical tree (we will discuss later how this tree can be constructed). Once we constructed the tree we can use softmax to select each branch of the tree. For example, given the following hierarchy and the value of the last hidden layer is $V$:
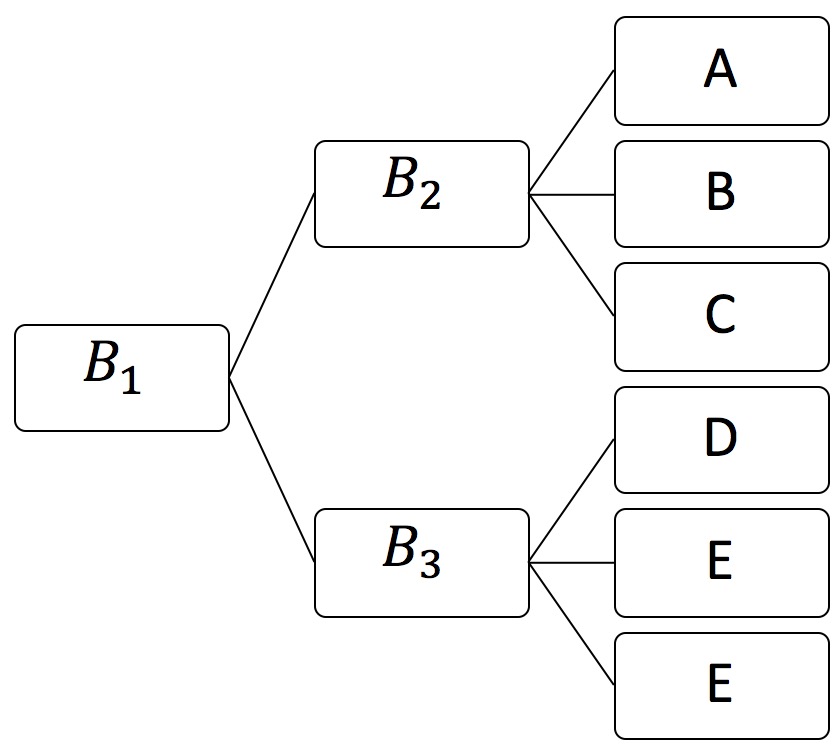
The probability of the network to predict "D" is (the probability of choosing the 2nd branch in $B_1$)(the probability of choosing the 1st branch on $B_3$). More formally: $P(class=D | V) = softmax(V \times W_{B_1})_1softmax(V \times W_{B_3})_0$
Now that we know what is hierarchical softmax we can start implementing it. We will create an hier_softmax that will receive an output hierarchy and will be able to calculate of the probability of an output given $V$ and to generate to most likely output given a vector $V$.
First we will define some auxiliary functions to handle trees:
from random import shuffle
from copy import copy
class TreeTools:
def __init__(self):
#memoization for _count_nodes functions
self._count_nodes_dict = {}
def _get_subtrees(self, tree):
yield tree
for subtree in tree:
if type(subtree) == list:
for x in self._get_subtrees(subtree):
yield x
# Returns pairs of paths and leafves of a tree
def _get_leaves_paths(self, tree):
for i, subtree in enumerate(tree):
if type(subtree) == list:
for path, value in self._get_leaves_paths(subtree):
yield [i] + path, value
else:
yield [i], subtree
# Returns the number of nodes in a tree (not including root)
def _count_nodes(self, tree):
if id(tree) in self._count_nodes_dict:
return self._count_nodes_dict[id(tree)]
size = 0
for node in tree:
if type(node) == list:
size += 1 + self._count_nodes(node)
self._count_nodes_dict[id(self._count_nodes_dict)] = size
return size
# Returns all the nodes in a path
def _get_nodes(self, tree, path):
next_node = 0
nodes = []
for decision in path:
nodes.append(next_node)
next_node += 1 + self._count_nodes(tree[:decision])
tree = tree[decision]
return nodes
# turns a list to a binary tree
def random_binary_full_tree(outputs):
outputs = copy(outputs)
shuffle(outputs)
while len(outputs) > 2:
temp_outputs = []
for i in range(0, len(outputs), 2):
if len(outputs) - (i+1) > 0:
temp_outputs.append([outputs[i], outputs[i+1]])
else:
temp_outputs.append(outputs[i])
outputs = temp_outputs
return outputs
Let's test the auxiliary functions:
tree = random_binary_full_tree(list(range(10)))
print('Our tree:',tree)
tree_tools = TreeTools()
print('All subtrees:')
for subtree in tree_tools._get_subtrees(tree):
print('\t',subtree)
print('All paths and leaves:')
for subtree in tree_tools._get_leaves_paths(tree):
print('\t',subtree)
print('Number of nodes in the tree:',tree_tools._count_nodes(tree))
print('all nodes in path [0, 0, 0, 0]:')
for nodes in tree_tools._get_nodes(tree, [0, 0, 0, 0]):
print('\t',nodes)
We now have everything we need to write the hierarchical softmax class:
import dynet as dy
class hier_softmax:
def __init__(self, tree, contex_size, model):
self._tree_tools = TreeTools()
self.str2weight = {}
#create a weight matrix and bias vector for each node in the tree
for i, subtree in enumerate(self._tree_tools._get_subtrees(tree)):
self.str2weight["softmax_node_"+str(i)+"_w"] = model.add_parameters((len(subtree), contex_size))
self.str2weight["softmax_node_" + str(i) + "_b"] = model.add_parameters(len(subtree))
#create a dictionary from each value to its path
value_to_path_and_nodes_dict = {}
for path, value in self._tree_tools._get_leaves_paths(tree):
nodes = self._tree_tools._get_nodes(tree, path)
value_to_path_and_nodes_dict[data.char2int[value]] = path, nodes
self.value_to_path_and_nodes_dict = value_to_path_and_nodes_dict
self.model = model
self.tree = tree
#get the loss on a given value (for training)
def get_loss(self, context, value):
loss = []
path, nodes = self.value_to_path_and_nodes_dict[value]
for p, n in zip(path, nodes):
w = dy.parameter(self.str2weight["softmax_node_"+str(n)+"_w"])
b = dy.parameter(self.str2weight["softmax_node_" + str(n) + "_b"])
probs = dy.softmax(w*context+b)
loss.append(-dy.log(dy.pick(probs, p)))
return dy.esum(loss)
#get the most likely
def generate(self, context):
best_value = None
best_loss = float(100000)
for value in self.value_to_path_and_nodes_dict:
loss = self.get_loss(context, value)
if loss < best_loss:
best_loss = loss
best_value = value
return best_value
Now we can test the performance improvement we can get from the hier_softmax. Again, we will learn the reverse function, but this time on a much bigger vocabulary
from random import choice, randrange
import data
data.set_vocab_size(1000)
print(data.sample_model(4, 5))
from tqdm import tqdm
MAX_STRING_LEN = 5
train_set = [data.sample_model(1, MAX_STRING_LEN) for _ in range(3000)]
val_set = [data.sample_model(1, MAX_STRING_LEN) for _ in range(50)]
def train(network, train_set, val_set, epochs = 20):
def get_val_set_loss(network, val_set):
loss = [network.get_loss(input_string, output_string).value() for input_string, output_string in val_set]
return sum(loss)
train_set = train_set*epochs
trainer = dy.SimpleSGDTrainer(network.model)
for i, training_example in enumerate(tqdm(train_set)):
input_string, output_string = training_example
loss = network.get_loss(input_string, output_string)
loss_value = loss.value()
loss.backward()
trainer.update()
print('loss on validation set:', get_val_set_loss(network, val_set))
Now that we have a large vocab data we can measure the training time of the attention model
from models import AttentionNetwork
ENC_RNN_NUM_OF_LAYERS = 1
DEC_RNN_NUM_OF_LAYERS = 1
EMBEDDINGS_SIZE = 200
ENC_STATE_SIZE = 210
DEC_STATE_SIZE = 210
att = AttentionNetwork(ENC_RNN_NUM_OF_LAYERS, DEC_RNN_NUM_OF_LAYERS, EMBEDDINGS_SIZE, ENC_STATE_SIZE, DEC_STATE_SIZE)
train(att, train_set, val_set)
Lets add hierarchical softmax to the model:
output_tree = random_binary_full_tree(data.characters)
RNN_BUILDER = dy.LSTMBuilder
class AttentionNetworkWithHierSoftmax(AttentionNetwork):
def __init__(self, enc_layers, dec_layers, embeddings_size, enc_state_size, dec_state_size, tree):
self.model = dy.Model()
# the embedding paramaters
self.embeddings = self.model.add_lookup_parameters((data.VOCAB_SIZE, embeddings_size))
# the rnns
self.ENC_RNN = RNN_BUILDER(enc_layers, embeddings_size, enc_state_size, self.model)
self.DEC_RNN = RNN_BUILDER(dec_layers, enc_state_size, dec_state_size, self.model)
# attention weights
self.attention_w1 = self.model.add_parameters((enc_state_size, enc_state_size))
self.attention_w2 = self.model.add_parameters((enc_state_size, dec_state_size))
self.attention_v = self.model.add_parameters((1, enc_state_size))
self.enc_state_size = enc_state_size
self.hier_softmax = hier_softmax(tree, dec_state_size, self.model)
def _get_probs(self, rnn_output, output_char):
return self.hier_softmax.get_loss(rnn_output, output_char)
def _predict(self, rnn_output):
return self.self.hier_softmax.generate(rnn_output)
att = AttentionNetworkWithHierSoftmax(
ENC_RNN_NUM_OF_LAYERS, DEC_RNN_NUM_OF_LAYERS, EMBEDDINGS_SIZE, ENC_STATE_SIZE, DEC_STATE_SIZE, output_tree)
train(att, train_set, val_set)
As we can see the hierarchical softmax shaved almost 12.5% off our training time. On real world data a vocabulary of 1,000 words is considered tiny so the gain should be considerably higher. Other difference from real word data is that the training examples will not be uniformly distributed and external information (such as wordnet) can further improve the hier softmax performance (http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.221.8829&rep=rep1&type=pdf#page=255)
More methods to deal with large vocabulary https://www.tensorflow.org/extras/candidate_sampling.pdf
About me: https://www.cs.bgu.ac.il/~talbau/