Topical Diversity in TD-QFS
Background information about the TD-QFS dataset can be found in (Baumel, Cohen and Elhadad).
QFS algorithms must combine query relevance assessment, central content identification, and redundancy avoidance. Frustratingly, state of the art algorithms designed for QFS do not significantly improve upon generic summarization methods, which ignore query relevance, when evaluated on traditional QFS datasets. We hypothesize this lack of success stems from the nature of the dataset.
The user scenario of this study is Query Focused Summarization (QFS): given an input document cluster and a query, generate an answer to the query which is a brief, well-organized, fluent answer to the query. We prepared a dataset of document clusters in the field of Consumer Health, and asked expert users (Medical Students) to generate summaries of document sets given various queries. All the manual summaries can be found here.
We reused the document clusters from the QCFS dataset. Those clusters were gathered by medical experts given the general topic (e.g., "asthma") from reliable sources such as NIH, Asthma NZ, U.S. National Library of Medicine, Wikipedia, Mayo Clinic, Alzheimer's Association.
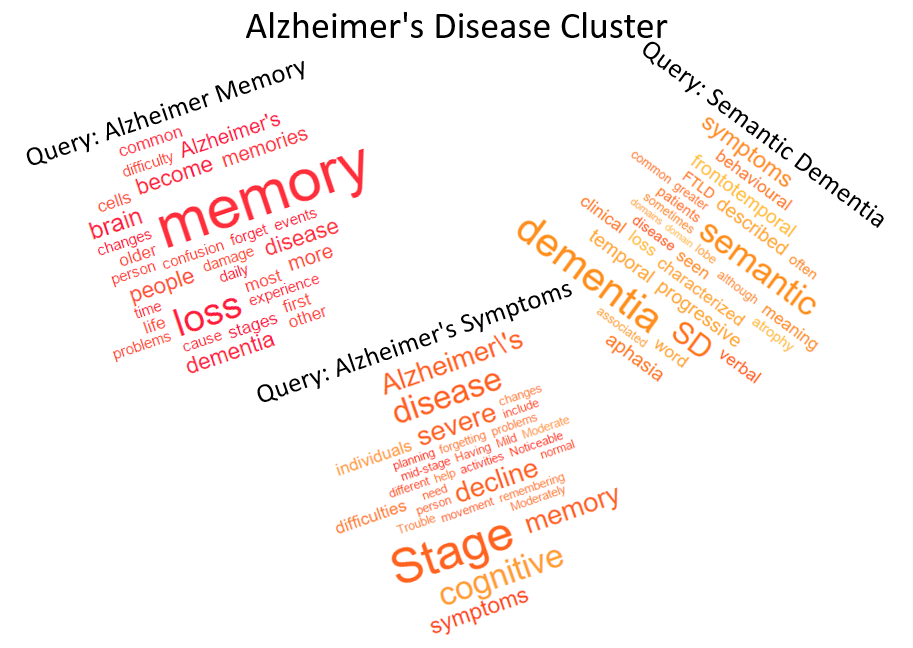
The dataset contains four document clusters: Asthma, Alzheimer's Disease, Lung Cancer and Obesity.
Topic concentration is an abstract property of a query-focused multi-document summarization dataset. It measures the extent to which the documents in a document cluster cover the same input query. The TD-QFS dataset was constructed in order to obtain lower topic concentration than is found in existing QFS datasets such as DUC 2005-2007.
We obtain this lower topic concentration by constructing each document cluster around a main query and several secondary queries. For example, one cluster in our dataset includes documents that are all relevant to "Alzheimer's disease" (the main query) and in addition, some of the documents cover specifically cognitive impairment, while others are about Alzheimer's symptoms, or semantic dementia (which are secondary queries within the same cluster).
The full list of queries used for this study can be found here.
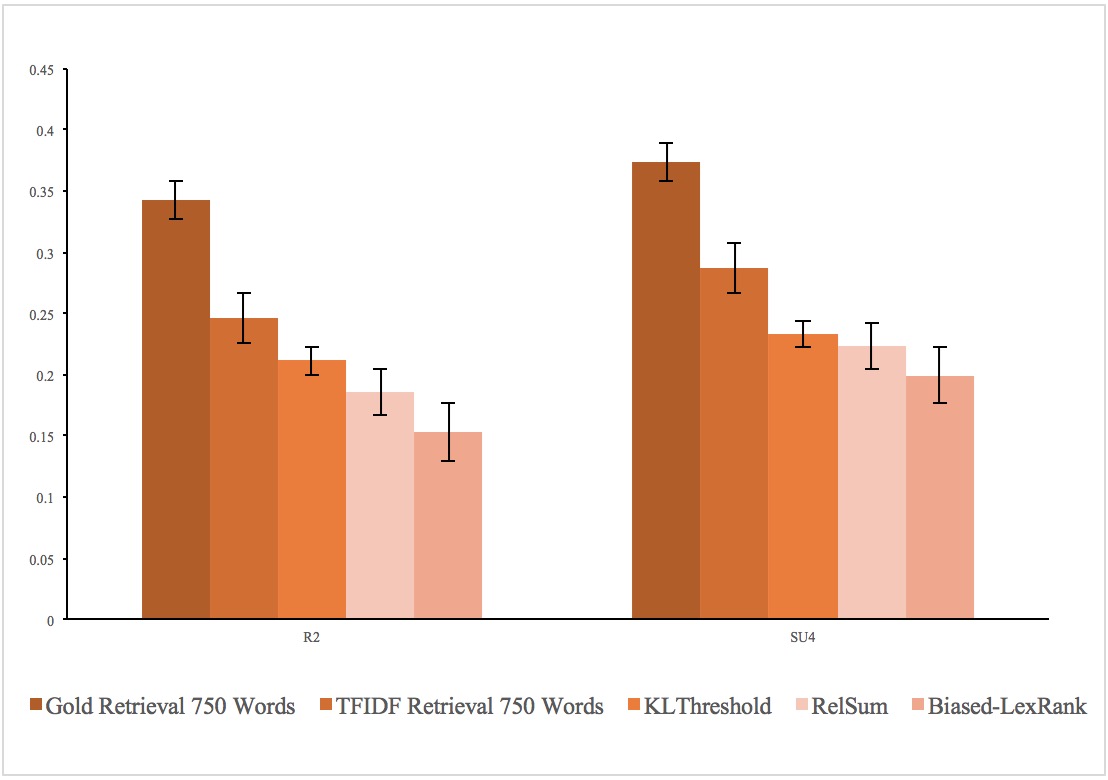
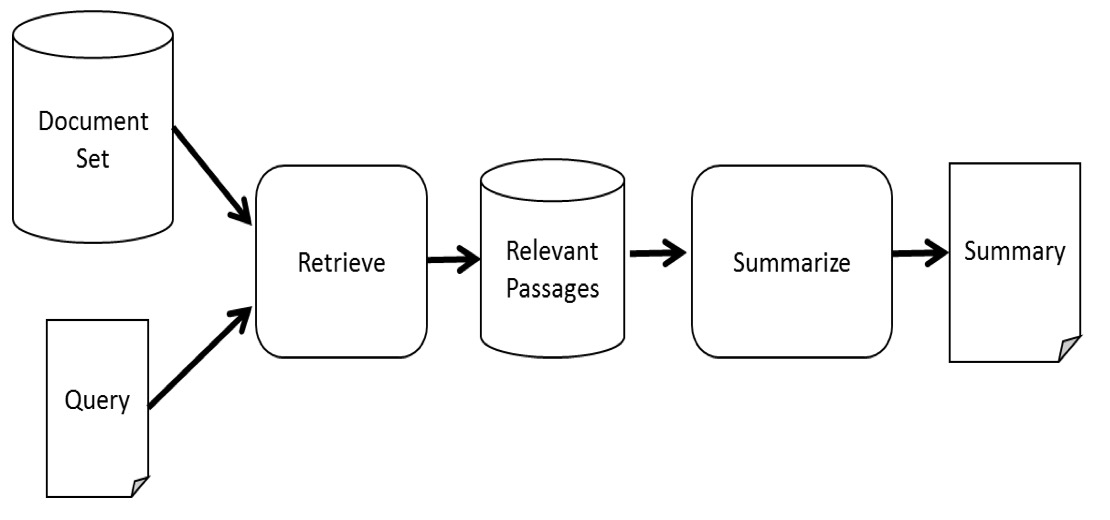
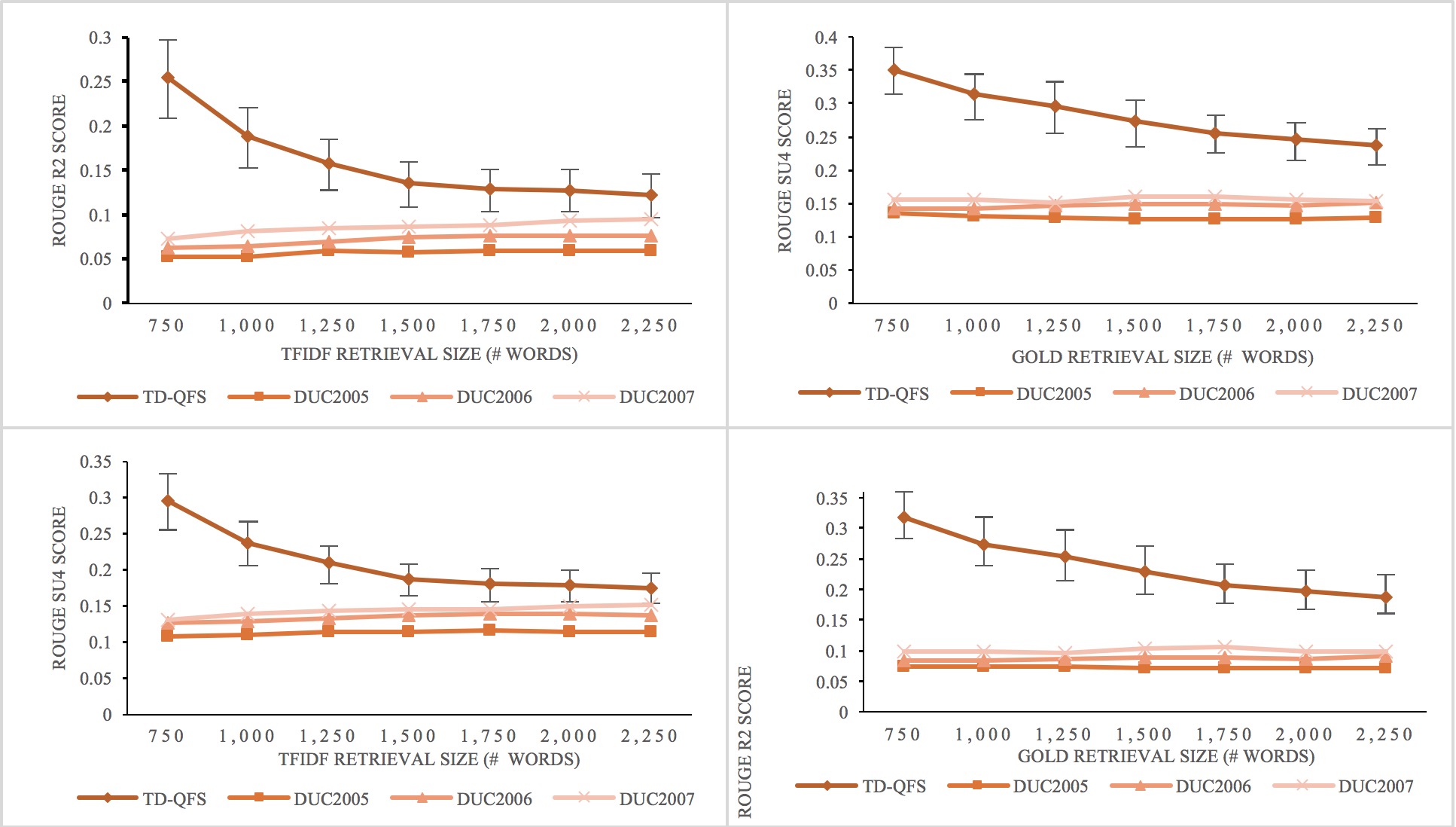
We compared the TD-QFS dataset topic concentration with DUC 2005-2007. We used a two-stage QFS scheme in order to quantify topic concentration in the datasets:
One can observe here that while DUC datasets maintain a flat curve regardless of retrieval size, the TD-QFS curves decrease sharply as less relevant content is kept in the second stage of the QFS scheme.
Several relevance-based QFS models were presented in the paper: